 Tables: Start Workflow for Each Row
Tables: Start Workflow for Each Row
Use this action to to start multiple instances of a Workflow, one for each row of a data table
This action is considered an “iterator”, and creates inline actions, which lets you embed a Workflow directly into another process. Check the Inline actions article to learn more, or see how to use iterators to repeat actions multiple times.
Use Case 
The Tables: Start Workflow for Each Row action starts an instance of a Workflow for each row of a specified data table. The instances that are started by this action are referred to as Helper Workflows or subprocesses and the overall functionality is also known as a batch process.
The action has many applications and should be considered whenever the same set of actions or tasks need to be repeated for multiple objects. Examples of this include: sending emails to a list of employees or customers, starting an instance for multiple cities/offices.
A typical use case is first using a Tables: Apply filters or Tables: Remove Duplicates in a Column action to first save specific rows of a data table into a new table and then using Tables: Start Workflow for Each Row on that resulting table.
How to configure this action
Because this action runs a series of steps for each row of a spreadsheet, you’ll need to choose which steps to run. You can choose to start a different Workflow, and use that Workflow’s actins; or create your own series of actions inline.
The values stored in the specific row of the data table can be referenced within the subprocess using the column name in {{field-names}} format.
All field values in the Workflow will be available in all subprocesses this action starts. However, the field values in the subprocesses will not be accessible in the main Workflow.
💡 Tip: If you test a Workflow with this action, the subprocesses will start in test mode as well.
Fields for this action
-
Workflow
- Optionally select a Workflow that will start off each row from a list of all Workflows available on your team. The list only includes Workflows you have permission to view. By default, Build Inline is selected, and allows you to create your own series of actions to run.
- If you have a Workflow that’s already built and ready to start, you can reference it by name, ID, or field.
-
Data table
- Select a table from a list of all tables available on your team. The list only includes tables you have permission to view.
- You can also reference a table stored in a field. Change the left hand drop-down to Use table via field then select from any field that is part of the process. Learn more.
- If necessary, you can enter the Table ID directly. Change the left hand drop-down to Use table by ID then enter the ID manually. Learn more.
- Select a table from a list of all tables available on your team. The list only includes tables you have permission to view.
-
Batch instance display name
- Input the name each sub process instance will adopt. Use field references, text, or references to a column in the form of:
columns['column-name']orcolumns['Column Display Name']- For example, with a run name of: “Sales report for
columns['sales team']”, the name of each run instance would change dynamically based on the row value in thesales teamcolumn, such as: “Sales report for team 1” or “Sales report for team 2”.
- For example, with a run name of: “Sales report for
- Input the name each sub process instance will adopt. Use field references, text, or references to a column in the form of:
-
Child run owner
- If left blank, all batch runs will be owned by the parent run owner. To have a different user own all batch runs, enter a user’s username or email in {{field-name}} format.
- 💡 Tip: To have the owner of each batch run assigned based on information in the data table, reference a data table column in columns[‘column-name’] or columns[‘Column Display Name’] format.
-
Deadline
- Select
TrueorFalsefrom the drop down to set whether the child instances should inherit the process deadline.- Select
Trueto pass the deadline from the parent process to the child instances. - Select
Falseor leave blank and no deadline will be set for the batch runs.
- Select
- Select
-
Owner
- Email address or username for owner of subprocesses,
{{field-names}}acceptable as well. If blank, will default to the owner of the batch Workflow
- Email address or username for owner of subprocesses,
-
Complete immediately
- Select
TrueorFalsefrom the drop down to set whether the parent Workflow should wait until all sub processes complete before marking this task as completed.- Select
Trueto have this task be marked complete as soon as all sub processes are started. - Select
Falseor leave blank to have this task stay open until all sub processes are finished.
- Select
- 💡 Tip: It’s recommended to leave this blank or
Falseif the sub processes are expected to return data back to the parent Workflow. By leaving this blank orFalse, the process will pause until all sub processes finish.
- Select
-
Output Field Prefix
- To help keep output fields organized, choose an output field prefix to add to the beginning of each output field name as this action may output more than one field.
- The step’s name is used as the prefix by default.
How to refer to values within the starter table from a Helper Workflow
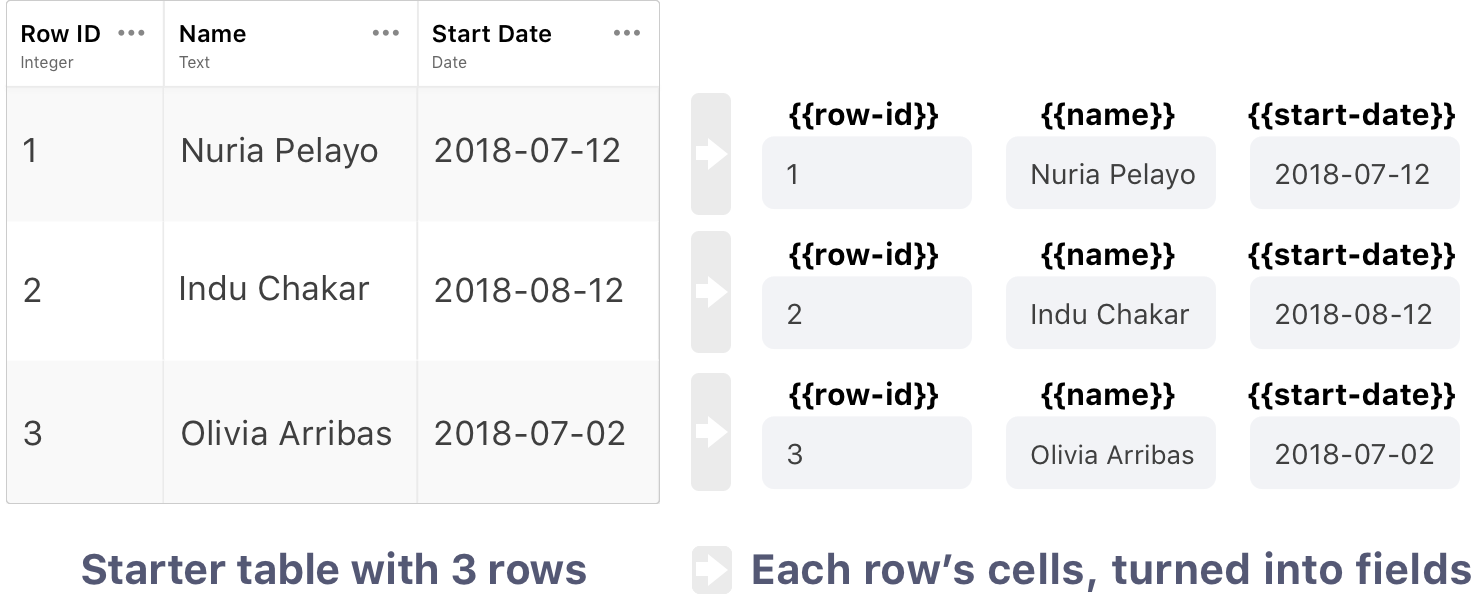
Each row of a table starts a unique Workflow instance. In each of those instances, the cells from the starter row are converted to referenceable fields. For example, a 20 column table would be turned into 20 fields.
Every cell from the table is available as a field based on the table headers. For example, each field from a table, Row ID, Name, and Start Date, is available using standard field reference notation: {{row-id}},{{name}}, and {{start-date}}.
The fields created from each row are available only in the instance that was started from the row. For example, the fields from the second row are only available in the second instance, and not in the 1st or 3rd instance.
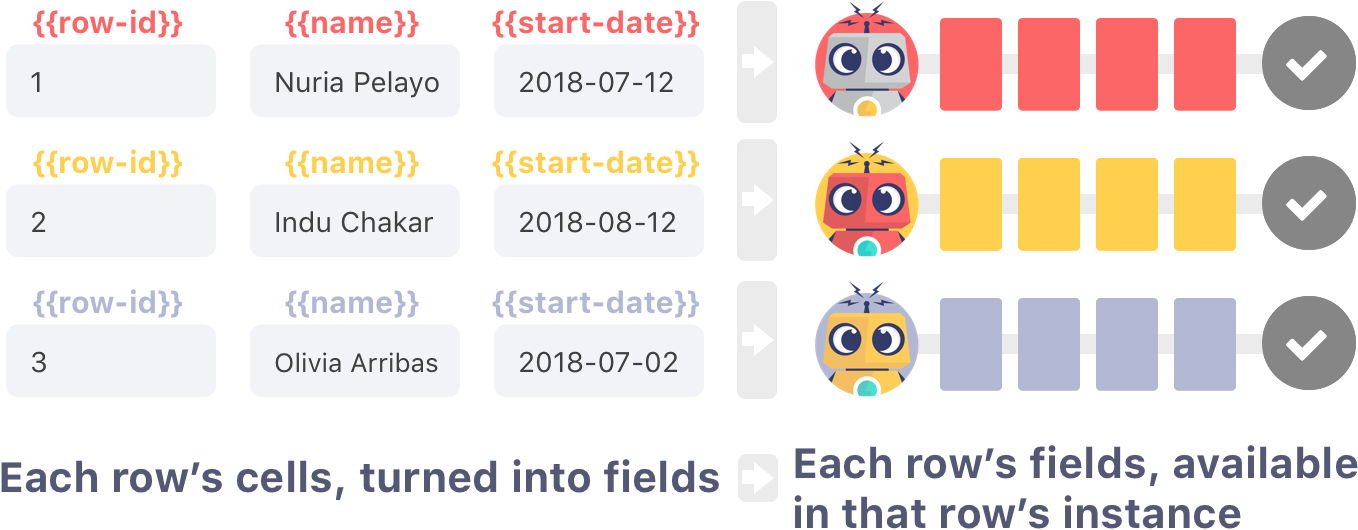
💡 Tip: These unique tables fields do not inherit the Output Field Prefix defined during configuration, they are referenced directly by their field name, e.g., {{start-date}}, not {{output-field-prefix--start-date}}.
How to send values from a Helper Workflow back to the parent Workflow
All field values in the starter Workflow will be available in the Helper Workflow. However, the field values in the Helper Workflow are not automatically accessible in the parent Workflow.
The best way to return fields and data from a Helper Workflow back to a parent Workflow is to store values in a data table. This data table acts as an in-between where both the helper and parent can add or edit data.

What will this output?
This action may generate multiple fields. To help keep output fields organized, the prefix above will be added to the beginning of each of the output field names, separated by two dashes. Each field will result as:{{output-field-prefix--output-field}}. Learn more
Output fields for this action
-
Number of Workflows
- The number of subprocesses started.
-
Successful Runs Data Table ID
- Stores the data table that logs the successful sub-process runs. Each successful run is a row in the table. The fields of each run are the columns of the table—including the
Run ID,Run display name.

- Stores the data table that logs the successful sub-process runs. Each successful run is a row in the table. The fields of each run are the columns of the table—including the
-
Failed Runs Data Table ID
- The ID for the Workflow Automation data table with the failed run data. This is the same data as the CSV. The table has a row for each run, and the columns Start date and Run ID.
-
Failed Runs
- The number of failed runs, such as if a row had incorrect data and a Workflow could not start from it.
-
Successful Runs
- The number of successful runs.
-
All runs started successfully
- If all sub-processes start successfully, outputs
true. If a 1 or more runs do not start successfully, outputsfalse.
- If all sub-processes start successfully, outputs
Thanks for your feedback
We update the Help Center daily, so expect changes soon.
Link Copied
Paste this URL anywhere to link straight to the section.