 Images: Optical Character Recognition (OCR)
Images: Optical Character Recognition (OCR)
Use this action to extract text from an image. The OCR action supports over 92 languages, including typed or printed text, handwriting, and multi-byte characters like Japanese, Chinese, and Korean. Check What languages are supported?. This action can scan PNG, PDF, JPEG, and JPG file types.

If you use this action to scan handwritten documents, OCR accuracy can vary dramatically based on the penmanship or handwriting style. This is a limitation of current OCR technology.
✅ Heads-up: This action is unable to extract text entered into a PDF file itself, such as a user-fillable form.
This is a premium action. By default, a premium action is not available in a team as there is an additional fee associated with it. Please contact PagerDuty Support to begin working with this action, or check the Premium Actions article.
Use case 
Since the OCR action extracts any text from an image, it’s easy to use in processes that handle incoming paper documents. For example, if a paper purchase order is scanned and submitted as an image, pull useful information from it with OCR instead of retyping it manually.
How to configure this action
This action works great in a Workflow that consistently scans similar images, such as purchasing orders. When incoming images are similar, the output fields will be easy to integrate into other actions.
The latest version supports scanning images up to 7.5mb and PDFs up to 2000 page or 100mb.
Fields for this action
-
Image file
- The image to be scanned, no greater than 10mb. This will most likely be a reference field to an image uploaded in another field.
-
Include output data table
- Select
TrueorFalsefrom the drop down to choose whether to output a full OCR data table in addition to the normal scanned output text.- Select
Trueto include the data table with a row for each word in the document. - Leave blank or select
Falseto only output the horizontal and vertical scans.
- Select
- Select
-
Output field name
- To help keep output fields organized, choose a prefix that will be added to the beginning of the output field name. The name you specify will become the output field prefix for the field.
What will this output?
The horizontal scan and vertical scan fields are the full text extracted from the document. Both should return similar results, but in a different order or layout. The difference between the horizontal and vertical scan is the direction in which the OCR action scans the document.
Example of horizontal and vertical scans
Horizontal scan

Vertical scan

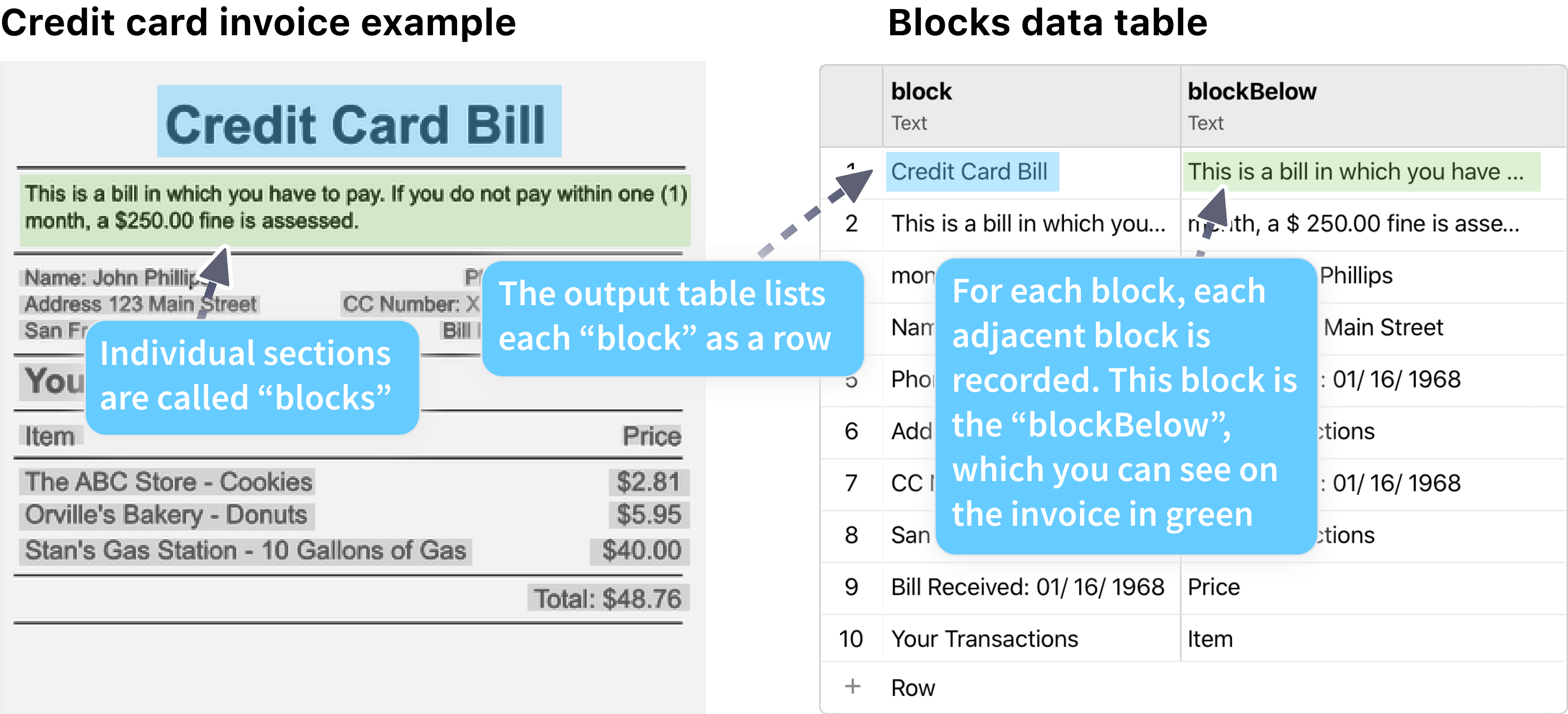
If Include output data table is TRUE, the action will also output a data table with more details. The data table includes a row for each block the OCR scan finds.
This action can output an immense amount of text depending on the document. If an output text field exceeds the field size system limit, there will be a fix task. The Workflow system limits field size limit is 128kB, or about 82 solid pages of text.
This action may generate multiple fields. To help keep output fields organized, the return field name above will be added to the beginning of each of the output field names, separated by two dashes. Each field will result as:{{return-field-name--output-field}}.
Output fields for this action
-
Characters Found
- Equals either True or False.
-
Horizontal Scan
- Provides the raw results of the horizontal OCR scan.
-
-
Vertical Scan
- Provides the raw results of the vertical OCR scan.
-
-
Data table
- If Include output data table is TRUE, the data table ID is output in this field. There is a data table row for each block extracted from the image. The different columns of each row are details for the block, such as which block is directly left or right of it. The columns for this table are:
-
Result Result Description blockthe block of text the word belongs to blockLeftthe block directly to the left of the current block blockRightthe block directly to the right of the current block blockAbovethe block directly above the current block blockBelowthe block directly below the current block pageNumberthe page number of the word within the PDF/document -

Get help with a problem or question
If something’s not working as expected, or you’re looking for suggestions, check through the options below.
What languages are supported?
The OCR action is able to detect a wide variety of languages, and multiple languages within each scan.
The following languages are considered fully supported.
| Language | English language name |
|---|---|
| Afrikaans | Afrikaans |
| shqiptar | Albanian |
| العربية | Arabic |
| Հայ | Armenian |
| беларускі | Belorussian |
| বাংলা | Bengali |
| български | Bulgarian |
| Català | Catalan |
| 普通话 | Chinese |
| Hrvatski | Croatian |
| Čeština | Czech |
| Dansk | Danish |
| Nederlands | Dutch |
| English | English |
| Eesti keel | Estonian |
| Filipino | Filipino |
| Suomi | Finnish |
| Français | French |
| Deutsch | German |
| Ελληνικά | Greek |
| ગુજરાતી | Gujarati |
| עברית | Hebrew |
| हिन्दी | Hindi |
| Magyar | Hungarian |
| Íslenska | Icelandic |
| Bahasa Indonesia | Indonesian |
| Italiano | Italian |
| 日本語 | Japanese |
| ಕನ್ನಡ | Kannada |
| ភាសាខ្មែរ | Khmer |
| 한국어 | Korean |
| ລາວ | Lao |
| Latviešu | Latvian |
| Lietuvių | Lithuanian |
| Македонски | Macedonian |
| Bahasa Melayu | Malay |
| മലയാളം | Malayalam |
| मराठी | Marathi |
| नेपाली | Nepali |
| Norsk | Norwegian |
| فارسی | Persian |
| Polski | Polish |
| Português | Portuguese |
| ਪੰਜਾਬੀ | Punjabi |
| Română | Romanian |
| Русский | Russian |
| Русский (старая орфография) | Russian |
| Српски | Serbian |
| Српски (латиница) | Serbian |
| Slovenčina | Slovak |
| Slovenščina | Slovenian |
| Español | Spanish |
| Svenska | Swedish |
| தமிழ் | Tamil |
| తెలుగు | Telugu |
| ไทย | Thai |
| Türkçe | Turkish |
| Українська | Ukrainian |
| Tiếng Việt | Vietnamese |
| Yiddish | Yiddish |
The following languages are considered to be partially supported.
| Language | English language name |
|---|---|
| አማርኛ | Amharic |
| Αρχαία ελληνικά | Ancient Greek |
| অসমীয়া | Assamese |
| Azərbaycan | Azerbaijani |
| Azərbaycan (qədim yazı) | Azerbaijani |
| Euskara | Basque |
| Bosanski | Bosnian |
| မြန်မာ | Burmese |
| Cebuano | Cebuano |
| ᏣᎳᎩ ᎦᏬᏂᎯᏍᏗ | Cherokee |
| dhivehi, dhivehi-bas | Dhivehi |
| རྫོང་ཁ་ | Dzonkha |
| Esperanto | Esperanto |
| Galego | Galician |
| ქართული | Georgian |
| Kreyòl Ayisyen | Haitian Creole |
| Gaeilge | Irish |
| Jawa | Javanese |
| Қазақ | Kazakh |
| Kirghiz | Kirghiz |
| Latine | Latin |
| Malti | Maltese |
| Монгол | Mongolian |
| ଓଡ଼ିଆ | Oriya |
| پښتو | Pashto |
| संस्कृतम् | Sanskrit |
| සිංහල | Sinhala |
| Swahili | Swahili |
| leššānā Suryāyā | Syriac |
| བོད་སྐད་ | Tibetan |
| ትግርኛ | Tigirinya |
| اردو | Urdu |
| oʻzbekcha | Uzbek |
| oʻzbekcha | Uzbek |
| Cymraeg | Welsh |
| IsiZulu | Zulu |
Why is text missing from a PDF form I scanned?
This action is unable to extract text entered into a PDF file itself, such as a user fillable form. This is a limitation of the PDF file type and OCR technology.
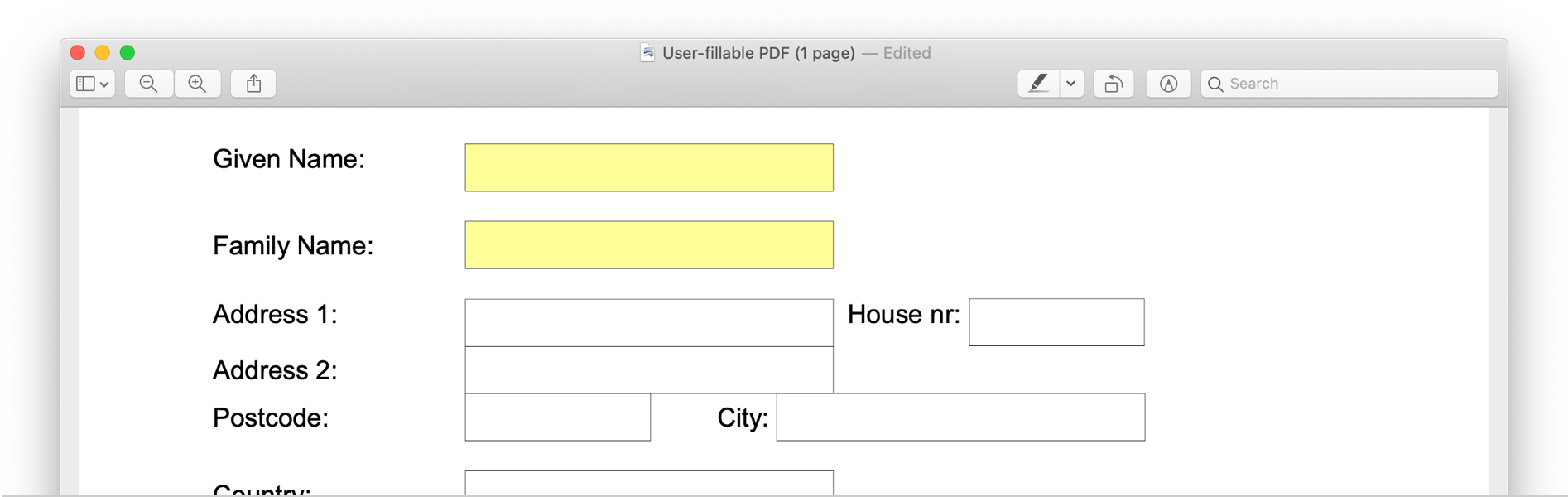
If it is possible to export the PDF as another file type, the user-filled forms are typically “flattened” into the file. For example, export the PDF as a PNG, then run it through OCR.
Thanks for your feedback
We update the Help Center daily, so expect changes soon.
Link Copied
Paste this URL anywhere to link straight to the section.